How GTO Wizard Solved PLO


Overview
How It Works
Just like GTO Wizard AI for No-Limit Hold’em, GTO Wizard AI PLO solutions are solved on the fly according to the parameters you input. These are solved using state-of-the-art technology that combines traditional solving methods with predictive neural networks to solve any spot within seconds!
The Status Quo
Traditional PLO solvers like Monker Solver use an algorithm similar to Monte Carlo CFR, where, at a high level, they navigate the game tree by sampling one hand for each player, playing out the hand, and updating the strategy based on the outcome. This process is repeated millions of times. To reduce the memory requirements and to achieve reasonable solving time, they often use abstraction on future streets, which force similar hands and board combinations to play the same strategy on these streets.
The main advantage of this class of algorithm is that (without abstractions), it can provably converge to a Nash Equilibrium if you let it run long enough. The main downsides are that it requires expensive hardware, long running time (multiple hours or even days for a single flop), poor convergence in low-frequency lines (because of updating a single hand at a time), and often heavy concessions like having a single bet size or small abstractions. Due to the high solving costs, products that offer solutions libraries based on these solvers are often highly limited; only offering a subset of flops, turns, and rivers.
GTO Wizard AI
Since its inception, GTO Wizard AI has had the philosophy that solving time is an incredibly important piece of the study process; fast and accurate solves mean a tight feedback loop that allows you to rapidly test hypotheses and learn more efficiently. However, PLO4 is a massive game; there are 270725 possible hands (200x more than Hold’em). From the start, we knew that achieving the desired latency of a few seconds per solve while not compromising accuracy would be a significant engineering and research effort.
We started by creating a state-of-the-art tabular solver for PLO4, i.e. a solver that can find a Nash Equilibrium in PLO4 trees, without any approximation like abstractions or neural networks. While this solver isn’t practical to use preflop or on the flop (the RAM required and solving time would be astronomical for most trees), it can be used to generate perfect data for the turn and river.
Armed with this solver, we started the training process: selfplay reinforcement learning. At a high level, this process consists of making the solver play against itself for a colossal number of hands, in order to generate data made up of the ranges of players at a given node and the corresponding EVs of every hand in their range, assuming the players were to play optimally from that point onwards. This data is then stored and used to train neural networks, whose job is to predict the EVs of every hand, given the public information (stack, pot, rake structure, etc.) and the ranges. This process happens over and over until the neural networks reach the desired accuracy.
At the end of this process, we obtain neural networks that can accurately predict the EVs of hands making it to the next street. We can then use these to do street-by-street solving, where only the current street is considered when solving. Note that this is the same exact process that powers our state-of-the-art No-Limit Hold’em solutions in GTO Wizard AI. By combining street-by-street solving with cutting-edge engineering efforts, we were able to reduce the solving time to a few seconds only.
The next thing you might be asking is:
{{question-mark}}
How accurate are these AI solutions?
{{/question-mark}}
River Benchmarks
As mentioned above, PLO4 heads-up solutions are solved on a street-by-street basis, meaning that when reaching any new street, including the river, the spot is solved in real-time. Given that the river is often the most important street in terms of the magnitude of potential EV mistakes and the EV difference of multiple sizes, it was very important for us to deliver the most accurate river solutions on the market. For that reason, rivers are solved exactly (no abstractions, no neural networks), down to a Nash distance smaller than 0.1% of the pot. We believe this makes our river solutions the most accurate on the market, as other tools like MonkerSolver don’t provide any Nash distance metrics.
Turn Benchmarks
Since solving exactly PLO4 from the flop would require up to terabytes of RAM and multiple days per solve on expensive hardware, we evaluated our AI solver on the turn, by following the exact same methodology used on the flop for heads-up NLH spots as our GTO Wizard AI Benchmarks article.
Methodology
We selected 200 random heads-up flop spots from our presolved library of 6-max solutions (SRP, 3BP, 4BP, …). We then assume normal play on the flop and sample a random turn node, weighted by the probability of getting to this node.
Then, for each turn spot:
- We compute the strategy for the turn with our AI solver, where we give each player two betting options (50% and 100%) and one raising option (100%) at every node.
- For each player:
- We nodelock their entire turn strategy into our tabular (exact) solver
- We solve the entire game tree (turn + river) while letting the other player make any strategic choice they want – given that one player’s entire strategy is locked on the turn
- We measure the EV loss of the locked player, after letting the other player maximally exploit the player’s fixed turn strategy
- We average the EV loss of each player
Here are the results:
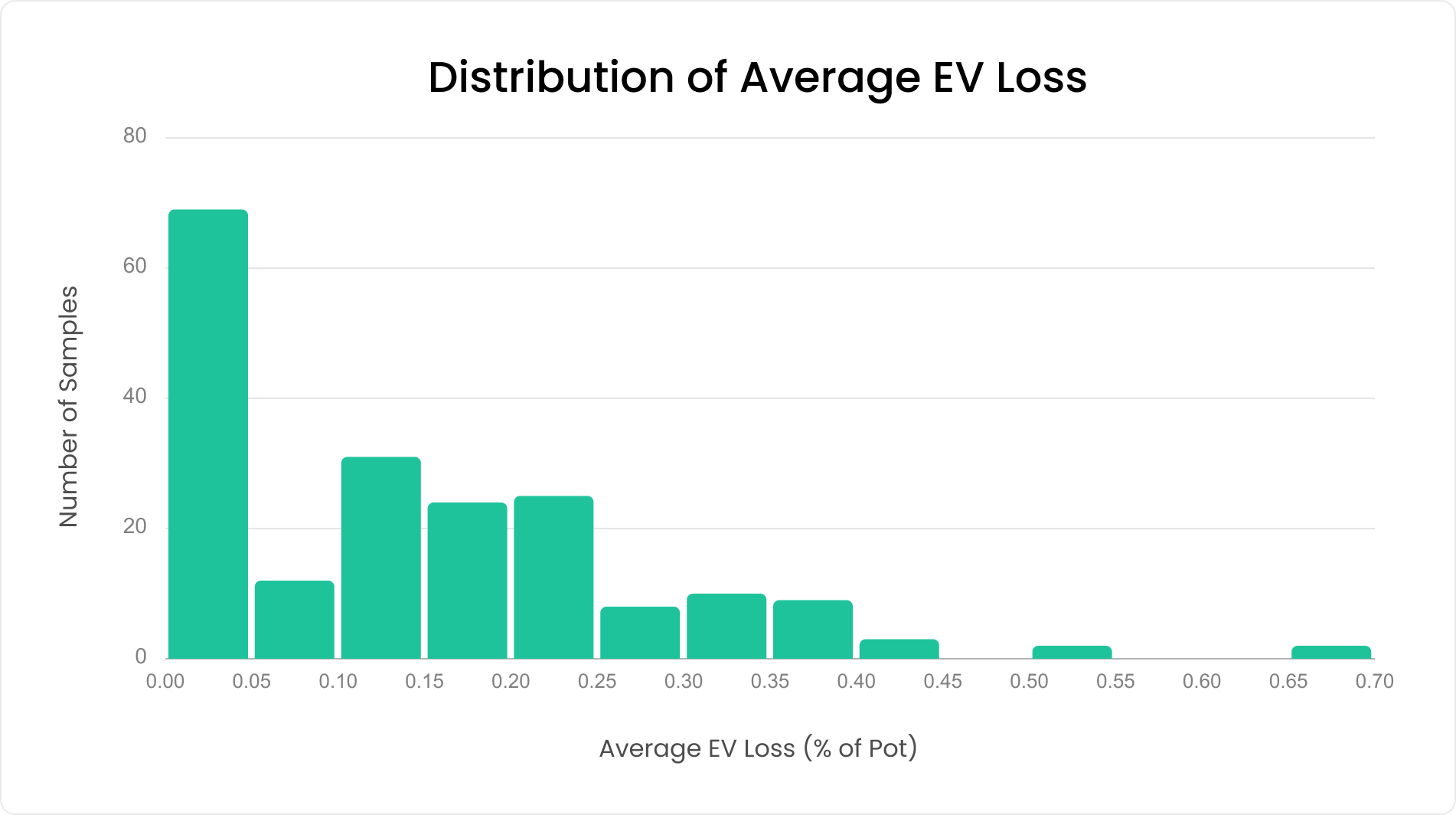
Over the 200 turn spots, we achieved an average EV loss of 0.14% of the pot, with 90% of turns having an average EV loss lower than 0.33% of the pot. However, note that this metric is sensitive to multiple parameters like the stack-to-pot-ratio, available sizes for both players, etc., so this should be taken only as an indication of the overall accuracy, not as an universal truth.
These results show that our neural networks are really precise at estimating the players EVs on future streets, which allows us to solve down to small Nash distances in a few seconds only. While we can’t show flop results since it would be too expensive to calculate the Nash distance on that street, we use the exact same methodology and algorithm as the turn to generate our flop solutions, so we’re confident that they achieve similar levels of accuracy.
At GTO Wizard AI, we’re consistently looking into pushing the state-of-the-art in poker AI, and we’re working relentlessly to make our solver more accurate every month. We also strive to provide you with transparency by taking the time to benchmark our algorithms and making sure these are the best solutions on the market. You can expect multiple improvement updates on this front in the future.
However, we understand that, more often than not, seeing is knowing. As such, our custom solutions builder is made infinitely flexible, allowing you to validate for yourself the accuracy of our solutions with other softwares. You can enter your own ranges, custom sizes, custom rake structures, etc., and compare for yourself.
Want to see it in action first? All users can test PLO4 right now, for free, by solving this flop: Q♠T♠7♥.
Looking Ahead
In summary, our PLO AI solver is built on the same theoretical foundation as our Hold’em solver, which translates into blazing fast solutions, without compromising accuracy. As such, you can also expect us to release in the near-future all the Hold’em solver features that you’ve come to expect: ICM solving, dynamic sizing (automatically finding the optimal single size), frequency locking, and player profiles.

GTO Wizard AI Custom Multiway Solving
At GTO Wizard AI, we’re proud to release our state-of-the-art preflop multiway solver! It supports up to 9 players, any cash game spot (chip EV and rake) and all our usual features (tree edits, nodelocking, profiles, etc.) – with the same speed and accuracy that we always aim to deliver.

GTO Wizard Themes Competition Winners
Hello Wizards, in August, we announced a themes competition, where we gave you a chance to win a 1-month Premium membership on GTO Wizard.

6 Reasons Why You Should Use GTO Wizard
6 Reasons Why You Should Use GTO Wizard. The primary problem with running your own solves is that it takes a massive amount of time, energy, and computation to run your own sims.